Gemini is a Boss
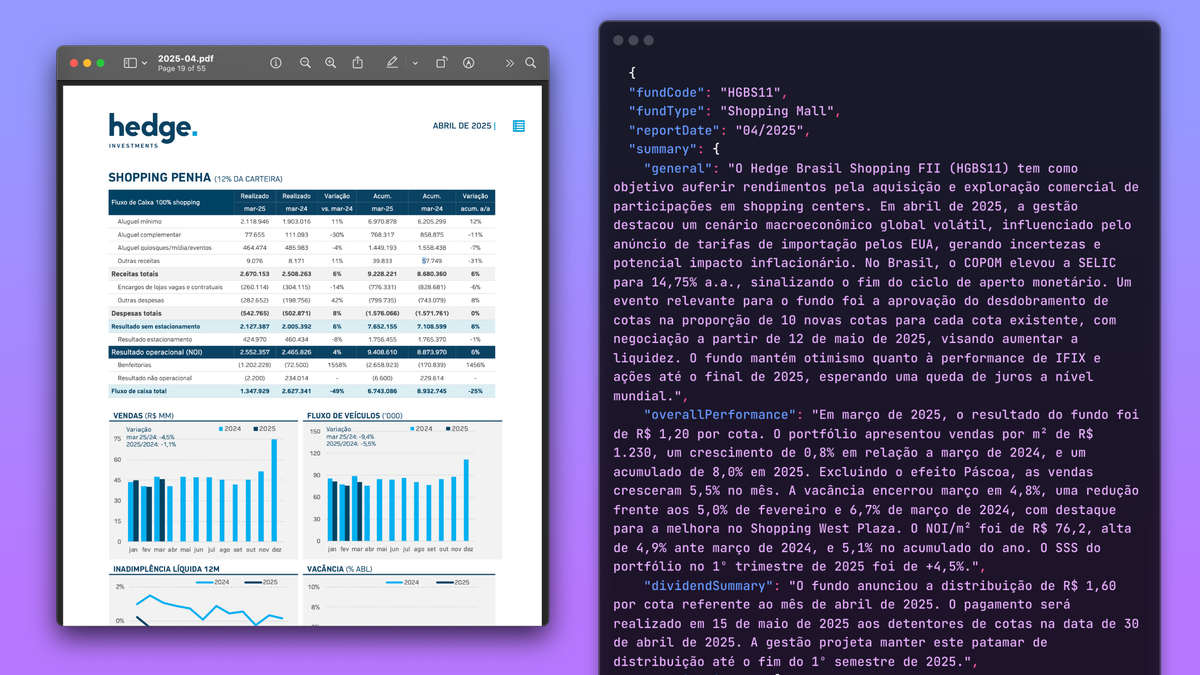
I hooked Gemini 2.5 Pro into my ResumoFII pipeline to pull structured data from Brazilian FII (REIT) PDF reports downloaded straight from the B3 stock exchange. These PDFs can be long, full of details and can take a while to read. The goal is to convert them into clean JSON without manual work.
In one test, it took 144 seconds to extract useful information from an 8.2 MB, 55-page fund report.
And the extracted information is exactly what I need. Having a uniform JSON schema across all funds is going to help with digesting all the useful tidbits of detail that Gemini is able to surface from the documents and will make analysis and visualization easier.
The ResumoFII Pipeline
Each job runs as follows:
- Download the fund's monthly report from B3
- Base-64 encode the PDF
- Call the Gemini API (streaming via Server-Sent Events)
- Parse each chunk as it arrives
- Strip out any markdown artifacts
- Validate the final JSON
This runs in Rust with Tokio Tasks. A local scheduler polls for new jobs every 30 seconds, spins up a task per job, downloads the file, and kicks off processing.
I'm currently executing a seed script to insert jobs but the idea is to automate that as well by running a nightly batch that will verify which fund reports already exist and insert jobs for new ones using a sliding window strategy.
In addition, the admin frontend could have a button on each fund page to insert new jobs for a specific month and year or for a custom range of months.
What's surprising is the accuracy of the output, at least on the small sample set of PDFs I tested.
It's good.
What Gemini Returned
The data extracted here is based on the latest April 2025 report for HGBS11 (shopping mall REIT). Gemini gave me a clean JSON response.

We get a simple dividend summary.

Here translated into English so non-Portuguese speakers can make sense of it.

But it goes even further with actual relevant metrics extracted from the report specific to the type of fund. There's data for metrics like net operating income per squared meter and sales per squared meter.
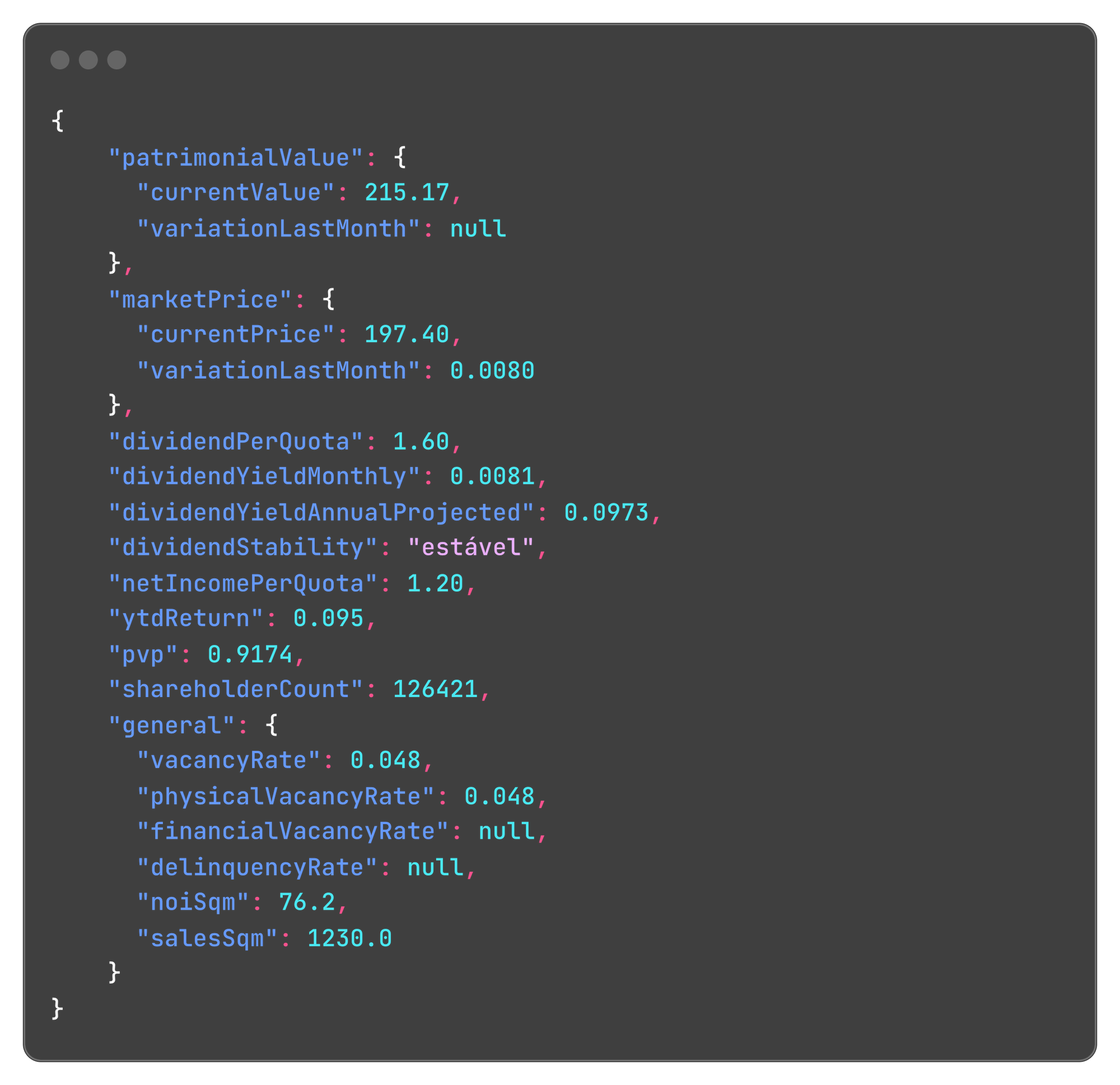
We've also got other high quality information, including:
- A narrative overview of fund strategy and macroeconomic context
- Highlights on an approved stock split
- Key challenges including Selic pressure (Brazil's reference interest rate)
- Full breakdown of debt structure with maturity, rates and guarantees
- Portfolio view with mall-by-mall metrics, trends and comments
The prompt I'm using is directing Gemini to return a data schema based on the fund type. Since this particular fund example is focused on shopping malls we get a list of JSON objects for each individual shopping mall that is part of this fund's portfolio.
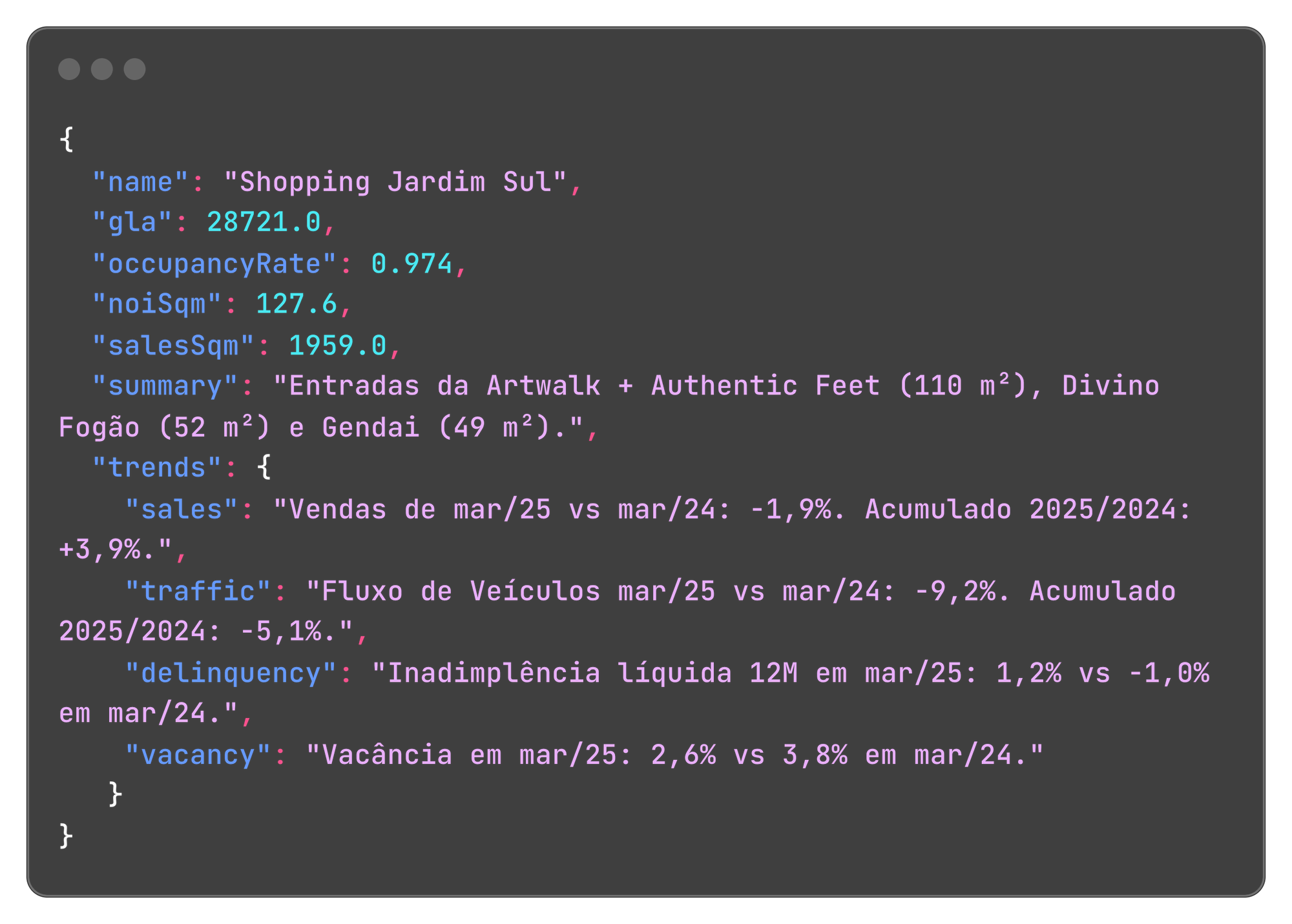
This is buried in a 55-page report, with images, tables and graphs. Gemini pulled it out, cleaned it up, and returned a usable object.
I gave it a PDF, a system prompt and a task to extract structured insight for a Brazilian REIT and it did exactly that.
This turns monthly reports, each with their own particular design and layout into consistent JSON snapshots that I can use to build ResumoFII's features on. Stuff like filtering, visualization and notifications.
What's Next
I need to persist the raw JSON and defer schema validation until the user views a report page.
That's the plan for the week.